
Agricultura de Precisión
Agricultura de precisión y la inteligencia artificial
Resumen
La inteligencia artificial tiene alto potencial junto a la agricultura de precisión pues pueden mejorar la competitividad y aumentar la sostenibilidad en comparación con los métodos tradicionales de producción de cultivos, y se ha convertido en un área cada vez más activa de investigación durante las últimas décadas. La guía del tractor utilizando los sistemas de sensores basados en el Sistema Global de Navegación por Satélite (GNSS) para el seguimiento de rutas y los sistemas de sensores locales para una navegación precisa en fila, en cultivos, en hileras y huertos ya han llegado para dar solución a muchas problemáticas existentes.
Estado del arte
Muchas decisiones de manejo de producción de cultivos pueden ser
informadas usando datos de imágenes aéreas de alta resolución que proporcionan información sobre la salud de los cultivos, influenciada por la fertilidad del suelo y la humedad. La humedad superficial del suelo es un componente clave del balance hídrico del suelo, que se ocupa de los intercambios de agua y energía en la interface superficie / atmósfera;
Sin embargo, raramente se utilizan datos de alta sensibilidad remota para adquirir valores de humedad del suelo.
Según el estudio realizado por (Leila HassanEsfahani *, 2016) , se desarrolló un modelo de red neuronal artificial (RNA) para cuantificar la efectividad del uso de imágenes espectrales para estimar la humedad superficial del suelo. El modelo produce estimaciones aceptables de la humedad superficial del suelo (RMSE) = 2,0, promedio de error absoluto (MAE) = 1,8, coeficiente de correlación (r) = 0,88, coeficiente de rendimiento (e) = 0,75 y
coeficiente de determinación (R2) = 0,77) combinando mediciones de campo con entradas de detección remota de bajo costo y fácilmente disponibles. Los datos espaciales (espectro visual, infrarrojo cercano, infrarrojo / térmico) son producidos por la plataforma AggieAir ™, que incluye un vehículo aéreo no tripulado (UAV) que permite a los usuarios recopilar imágenes aéreas a bajo precio y altas resoluciones espaciales y temporales. Este estudio reporta el desarrollo de un modelo de ANN que traduce las imágenes de AggieAir ™ en estimaciones de la humedad superficial del suelo para un gran campo irrigado por un sistema de rociadores de pivote central.
El objetivo de esta investigación es generar estimaciones de la humedad superficial del suelo (SSM) utilizando datos de alta resolución y de detección remota, recogidos a una resolución de 15 cm de píxel, como insumos para un algoritmo de máquina de aprendizaje (RNAs) desarrollado bajo aprendizaje supervisado
Procedimientos.
Las RNAs se usan para construir el modelo de estimación SSM. Hasta donde se conoce, este es el primer estudio que documenta la estimación de la humedad superficial del suelo usando datos de detección remota a una resolución espacial tan fina y fácilmente disponible en el sentido de resolución temporal. Los resultados no sólo contribuirán a la validación eficiente y fiable de la teledetección multiespectral de alta resolución, sino también a una mejor utilización de los productos de humedad del suelo de detección remota para mejorar el modelado y la programación del riego.
Luego de un estudio de distintos enfoques los investigadores han tenido que buscar herramientas de modelado basadas en datos, tales como redes neuronales artificiales (RNAs), máquinas vectoriales de apoyo (SVMs) y máquinas de vector de relevancia (RVMs), para estimar la húmedad del suelo [3,23,24,25,26,27].
Se desarrolló un modelo de red neuronal de alimentación en tres capas (FFNN) que incluye neuronas de entrada «I», «h» neuronas ocultas y «o» neuronas de salida, que se pueden representar simbólicamente como RNAs (i, h, o) [28]. Los pesos de conexión y el sesgo conectan estas neuronas. La entrada se multiplica por los pesos de conexión. Estos productos se suman simplemente, se alimentan a través de una función de transferencia para generar un resultado y, a continuación, la salida. Las neuronas de capas ocultas suelen utilizar una función de activación sigmoidal, mientras que las neuronas de capa de salida utilizan una función de activación lineal. Las funciones de activación se utilizan para transformar entradas a salidas específicas con un procedimiento de regresión no lineal. Cada modelo de ANN requiere operaciones de entrenamiento y pruebas. En la operación de entrenamiento, al minimizar la función de costo (Mean Squared Error (MSE) en este estudio), se optimizan los pesos de conexión y los valores de polarización. Una vez entrenado, un conjunto independiente de datos que no se utilizó para la formación se aplica para probar el modelo de red neuronal [26]. El tema que amenaza la aplicación de los modelos basados en ANN es la aleatoriedad de la producción prevista, que se fija en este estudio [29]. Esto se llevó a cabo mediante la aplicación de la función de generación de semillas.
Dado que los pesos se inicializan al azar, la función de generación de semillas se restableció para superar la aleatoriedad de los resultados mediante la fijación de la inicialización de pesos y hacer los resultados reproducibles. También se ejecutaron los modelos para una amplia gama de valores de semilla. La operación de entrenamiento de las RNA se realizó mediante un algoritmo de retropropagación, que es el algoritmo de entrenamiento supervisado más comúnmente utilizado en las redes de avance múltiple. Los pesos de la red son modificados simultáneamente por el algoritmo de retropropagación que busca minimizar la diferencia entre los objetivos y las salidas calculadas. En este tipo de algoritmo, la operación de procesamiento se realiza en una dirección hacia adelante, desde entradas hasta capas ocultas y, finalmente, hasta una capa de salida [30].
Un método de retropropagación utiliza un método de error cuadrático mínimo y una regla delta generalizada para optimizar los pesos de la red. La regla de la cadena derivada y el método de pendientegradiente se utilizan para ajustar los pesos de la red [31]. El paso directo y el paso inverso son dos fases principales de la operación de entrenamiento. En la primera fase, los datos de entrada se multiplican por los pesos iniciales, formando insumos ponderados que luego se añaden para dar la red a cada neurona. Esta red genera la salida de la neurona después de pasar por una función de activación o transferencia.
En las redes de retropropagación, un derivado de la función de activación modifica los pesos de la red. Por lo tanto, las funciones de transferencia continua están dirigidas. La función de transferencia Log-sigmoide y la función de transferencia de la sigmoide tangencial hiperbólica son las funciones de transferencia continua más comunes en las redes de retropropagación [32]. La función de transferencia Log-sigmoide se utilizó en este estudio. La salida de la neurona se transmite a la siguiente capa como una entrada, y este procedimiento se repite hasta que alcanza la capa de salida. El error entre las salidas de la red y las salidas de destino se calcula al final de cada paso de avance y se comprueba con un valor específico. Si el error pasó este valor, el procedimiento continúa con un paso inverso; De lo contrario, el entrenamiento se detiene [33]. En el paso inverso, los pesos en la red se modifican usando el valor de error. La modificación de pesos en la capa de salida es diferente de la modificación de pesos en las capas ocultas. En la capa de salida, se proporcionan las salidas objetivo, mientras que en las capas intermedias, los valores objetivo no existen [31]. Por lo tanto, la propagación posterior utiliza las derivadas de la función objetivo con respecto a los pesos en toda la red para distribuir el error a las neuronas en cada capa en toda la red [33].
2.2. Selección de posibles variables de entrada Uno de los problemas críticos en el prendizaje de algoritmos de máquina de aprendizaje como RNAs es seleccionar las variables de entrada apropiadas. La idea es elegir la combinación de variables que están altamente correlacionadas con la humedad del suelo. Estudios anteriores han demostrado una buena correlación entre el contenido de agua en el suelo y la temperatura de la piel infrarroja (IR) y el índice de vegetación de diferencias normalizadas (NDVI), y entre la tasa de calentamiento IR y las imágenes térmicas [34, 35].
Optical y microondas de datos de detección remota se han utilizado para la superficie del suelo balance de energía de modelado [6, 11, 12, 36]. Después de recolectar estas variables de conjuntos de datos independientes, la correlación y la dependencia entre estas variables se evaluaron en el estudio presentado.
Algunos índices de vegetación (VIs) se consideran como variables de entrada con algunas contribuciones en las estimaciones de la humedad del suelo [4, 37, 38, 39].
Este trabajo demuestra la aplicación de una tecnología de teledetección de alta resolución (AggieAir) para estimar la humedad superficial del suelo como una pieza clave de información en el manejo del agua de riego. Las imágenes multiespectrales de alta resolución, en combinación con el muestreo en tierra, proporcionaron suficiente información para los enfoques de modelado para estimar con precisión la humedad superficial del suelo distribuida espacialmente.
Este artículo presenta los resultados de un enfoque de modelado utilizando ANN en concierto con el tiempo y la información específica del sitio. Paralelamente a otros enfoques de modelado, como los algoritmos de minería de datos o la regresión lineal, el modelo de RNA se calibra para este estudio dentro de las condiciones de la información recogida, incluyendo las mediciones de humedad del suelo, textura del suelo, tipo de cultivo e
imágenes multiespectrales de alta resolución.
Por otra parte otro trabajo realizado por (Center, 2016) plantea que la última generación de redes neuronales convolucionales (CNNs) ha logrado resultados impresionantes en el campo de la clasificación de imágenes. Este trabajo se refiere a un nuevo enfoque para el desarrollo del modelo de reconocimiento de enfermedades vegetales, basado en la clasificación de imágenes foliares , mediante el uso de redes convolucionales profundas. La nueva forma de entrenamiento y la metodología utilizada facilitan una implementación rápida y sencilla del sistema en la práctica. El modelo desarrollado es capaz de reconocer 13 tipos diferentes de enfermedades de las plantas de las hojas sanas, con la capacidad de distinguir las hojas de las plantas de sus alrededores.
Se nombra Caffe, un marco de aprendizaje profundo que se utilizó para realizar el entrenamiento de CNN. Los resultados experimentales en el modelo desarrollado alcanzaron una precisión entre 91% y 98%, para pruebas de clase separadas, en promedio 96,3%.
Dado el uso excesivo de plaguicidas puede causar el desarrollo de resistencia a largo plazo de los patógenos, reduciendo drásticamente la capacidad de combatir. El diagnóstico oportuno y preciso de las enfermedades de las plantas es uno de los pilares de la agricultura de precisión [7]. Es fundamental prevenir el desperdicio innecesario de recursos financieros y de otro tipo, logrando así una producción más sana, abordando el problema de desarrollo a largo plazo de la resistencia a los patógenos y mitigando los efectos negativos del cambio climático.
Los avances en la visión por computadora ofrecen una oportunidad para ampliar y mejorar la práctica de la protección fitosanitaria precisa y ampliar el mercado de las aplicaciones de visión por computadora en el campo de la agricultura de precisión.
La utilización de técnicas comunes de procesamiento de imágenes digitales, tales como el análisis de color y umbral [9] se utilizaron con el objetivo de la detección y clasificación de enfermedades de las plantas.
Varios enfoques diferentes se utilizan actualmente para la detección de enfermedades de las plantas y más comunes son las redes neuronales artificiales (RNAs) [10] y Support Vector Machines (SVM) [11]. Se combinan con diferentes métodos de preprocesamiento de imágenes a favor de una mejor. Existen algunos enfoques que aplican la propagación posterior de las redes neuronales, que consiste en una entrada, una salida y una capa oculta para las necesidades de identificar las especies de hoja, plaga o enfermedad; Este modelo fue propuesto por los autores en [21]. Ellos
desarrollaron un modelo de software, para sugerir medidas correctivas para el manejo de plagas o enfermedades en cultivos agrícolas.
Otra técnica propuesta por los autores en [22] incorpora las características extraídas por Optimización de enjambre de partículas (PSO) [23] y la red neural hacia adelante en la dirección de determinar la mancha de la hoja lesionada de algodón y mejorar la precisión del sistema con la precisión global final Del 95%.
Además, la detección y diferenciación de las enfermedades de las plantas puede lograrse utilizando algoritmos de Vector Vector. Esta técnica se aplicó para las enfermedades de la remolacha azucarera y se presentó en [24], donde, dependiendo del tipo y etapa de la enfermedad, la precisión de clasificación fue entre 65% y 90%. tracción de características.
Del mismo modo, hay métodos que combinan la extracción de características y Neural Network Ensemble (NNE) para el reconocimiento de enfermedades de las plantas. Mediante la formación de un número definido de redes neuronales y la combinación de sus resultados después de
eso, NNE ofrece una mejor generalización de la capacidad de aprendizaje [25]. Este método se implementó sólo para el reconocimiento de las enfermedades de hoja de té con una precisión final de pruebas del 91% [26]
Otro enfoque basado en las imágenes de las hojas y el uso de RNA como una técnica para la detección automática y clasificación de enfermedades de las plantas se utilizó en conjunción con los medios como un procedimiento de agrupamiento propuesto por los autores en [27]. ANN consistía en 10 capas ocultas. El número de resultados fue 6, que fue el número de clases que
representan cinco enfermedades junto con el caso de una hoja sana. En promedio, la precisión de la clasificación utilizando este enfoque fue del 94,67%.
Se propuso el entrenamiento de la red neuronal convolucional profunda para hacer un modelo de clasificación de imágenes a partir de un conjunto de datos.
Existen algunas vanguardias de los marcos de aprendizaje profundo, como la biblioteca de Python Theano [37] y la biblioteca de aprendizaje de la máquina que se extiende Lua, Torch7 [38]. Además, existe Caffe, un marco de aprendizaje profundo de código abierto desarrollado por la BVLC [39] que contiene el modelo preconcebido CaffeNet de referencia. Para el propósito de esta investigación, este marco fue utilizado, junto con el conjunto de pesos aprendidos en un conjunto de datos muy grande, ImageNet [40].
Caffe marco es adecuado tanto para los experimentos de investigación y el
despliegue de la industria. El núcleo del framework se desarrolla en C ++ y
proporciona interfaces de línea de comandos, Python y MATLAB. La
integración de Caffe con la biblioteca cuDNN acelera los modelos Caffe [41, 42]. CaffeNet es una profunda CNN que tiene múltiples capas que progresivamente calcular las características de las imágenes de entrada [43]. Específicamente, la red contiene ocho capas de aprendizaje y cinco convolucional y tres capas totalmente conectadas [44].
La arquitectura de CaffeNet se considera un punto de partida, pero se modifica y se ajusta para soportar nuestras 15 categorías (clases). La última capa se alteró y la salida de la capa softmax se parametrizó a los requerimientos del estudio presentado.
La capa convolucional es el elemento esencial de la red neuronal convolucional. Los parámetros de la capa se componen de un conjunto de núcleos aprendibles que poseen un campo receptivo pequeño pero que se extienden a través de toda la profundidad del volumen de entrada [45].
Lo antes explicado recae en la conclusión que esta aplicación sirve como ayuda a los agricultores (independientemente del nivel de experiencia), permitiendo el reconocimiento rápido y eficiente de las enfermedades de las plantas y facilitando el proceso de toma de decisiones cuando
se trata del uso de pesticidas químicos.
Y para concluir una experiencia cubana citada por (Dr.C. Neeldes Matos Ramírez, (abril-mayo-junio), 2014) donde expresa que la producción de caña en Cuba de manera eficiente se ha vuelto una necesidad, más que un objetivo, por tal motivo en la segunda mitad del decenio del siglo XXI se han estado introduciendo nuevas tecnologías y máquinas que den respuesta a esta situación. El trabajo del complejo cosecha – transporte – recepción
es decisivo en el propósito de disminuir los costos de producción de azúcar, en tal sentido la introducción de la ciencia y la técnica en este campo clasifican como la única alternativa para alcanzar los objetivos de producir azúcar de calidad a bajos costos. La Inteligencia Artificial (IA) es una ciencia que estudia el pensamiento y el diseño de máquinas inteligentes, es decir el estudio y la simulación de las actividades cognoscitivas del hombre. En
este trabajo se exponen las aplicaciones de los algoritmos de la IA en la obtención de la composición óptima, del proceso cosecha-transporte-recepción de la caña de azúcar.


Definición de los casos
Un caso estará compuesto por un vector de datos y una clasificación. Cada uno constituirá la información experimental del Proceso cosecha- transporte-recepción de cada Central. Con esos datos experimentales se confeccionaría la BC del proceso cosecha-transporte-recepción.
Ejemplo de la BC, (Tabla 2).
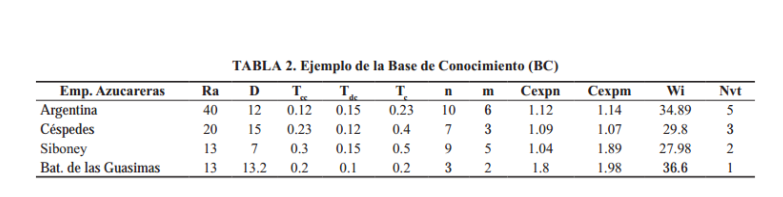
En el trabajo se muestran las posibilidades que pueden brindar las técnicas de Inteligencia artificial (IA) para la solución de problemas reales relacionados con la toma de decisiones y la racionalización de los recursos de la economía, en un importante renglón del país. Es posible utilizar este método en la organización científica de las transportaciones de la caña de azúcar.
Bibliografía
Center, B. V. (29 de mayo de 2016). Inteligencia Computacional y Neurociencia. Obtenido de
http://dx.doi.org/10.1155/2016/3289801
Dr.C. Neeldes Matos Ramírez, L. Y. ((abril-mayo-junio), 2014). La inteligencia artificial. Nuevo enfoque en la
evaluación de las máquinas en el complejo cosecha – transporte – recepción de la caña de azúcar.
INGENIERÍA AGRÍCOLA, ISSN-2326-1545, RNPS-0622, Vol. 4, No. 2, pp. 60-64.
Leila Hassan-Esfahani *, A. T.-R. (2016). Assessment of Surface Soil Moisture Using High-Resolution MultiSpectral Imagery and Artificial Neural Networks. Scorpus.
